Let say you want to scrape 9000 pages of a website. Order doesn’t matter and the real bottleneck is the ping to the external server. Code like this:
data = {}
def network_task(data,page)
http.get('url?page='+page) #pseudo code
...
data[page] = parsed_page
end
for x in 0..9000
network_task(data,x)
end
puts dataIs going to take around RTT*9000 seconds to run. Where RTT is the round trip time to the server.
However the webserver can probably handle at least 5 simulteanous request, so there’s no need for pages 2,3,4,5 to wait on page 1 to complete. To accomplish this we’ll use Ruby’s built in threads. Threads accept a block of code and execute it outside the normal flow of the program. You can then re-join the threads when you want to be sure they have completed.
A few examples to give you an idea of how this works:
x = [1]
Thread.new { x<<2 }
puts x
# outputs 1
x = [1]
Thread.new {
x << 2
puts x
end
# outputs 1, 2
x = [1]
Thread.new {
x << 2
puts x
end
puts x
# first outputs 1
# then outputs 1, 2
x = [1]
thread = Thread.new {
x << 2
}
thread.join()
puts x
# outputs 1, 2Okay with the basic idea of threads in mind we can then parallelize our above program to run serveral network requests simultaneously. First we will establish a queue of tasks for all threads to pull from.
num_threads = 10
threads = [] # array of threads
queue = Queue.new
pages = 0..9000
pages.each do |num| {
queue << num # put 0 through 9000 in the queue
}
data = {}
def network_task(data,page)
http.get('url?page='+page) #pseudo code
...
data[page] = parsed_page
end
num_threads.each do |thrd| {
threads << Thread.new { # add the new thread to the array
while queue.length != 0 {
page = queue.pop()
network_task(data,page)
}
}
}
threads.each do |thrd| {
thrd.join() # Wait for all threads to complete here
}
puts dataNow we are making multiple network requests at the same time with can get a total runtime closer to 9000*RTT/num_threads. Bear in mind this inverse relationship between number of threads and total time isn’t entirely accurate and you will reach a plateau. When I was scraping www.herpmapper.org/ for another project, I generated the following data:
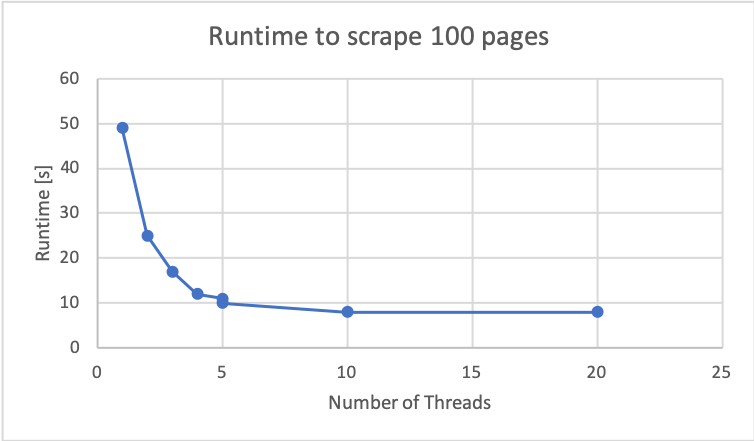
From 1 thread to 4 I see a near 500% speed up.
As you can see past 4/5 threads there really wasn’t a performance improvement. And while this is specific to their server the idea should be clear: there are huge performance improvements available BUT simply using as many threads as possible is not going to increase performance past some bottleneck. And will likely decrease performance at some point due to overhead.
Hope this helps you get started in threading with ruby.